多模态API
"All things that are naturally connected ought to be taught in combination" - John Amos Comenius, "Orbis Sensualium Pictus", 1658
人类处理知识的方式,是同时通过多种数据输入模式进行的。 我们的学习方式、我们的体验都是多模态的。 我们不仅仅依赖视觉、听觉或文本。
与这些原则相悖的是,机器学习常常侧重于针对处理单一模态的专用模型。 例如,我们为诸如文本转语音或语音转文本的任务开发了音频模型,以及为对象检测和分类等任务开发了计算机视觉模型。
然而,新的一波多模态大型语言模型开始涌现。其中包括OpenAI的GPT-4o、Google的Vertex AI Gemini 1.5、Anthropic的Claude3,以及开源产品Llama3.2、LLaVA和BakLLaVA,这些模型能够接受多种输入形式,包括文本、图像、音频和视频,并通过整合这些输入来生成文本回应。
| 多模态大型语言模型(LLM)功能使模型能够结合图像、音频或视频等其他模态处理和生成文本。 |
Spring AI 多模态
多模态是指模型同时理解和处理来自多种来源信息的能力,这些来源包括文本、图像、音频及其他数据格式。
Spring AI 消息 API 提供了支持多模态大型语言模型所需的所有抽象。
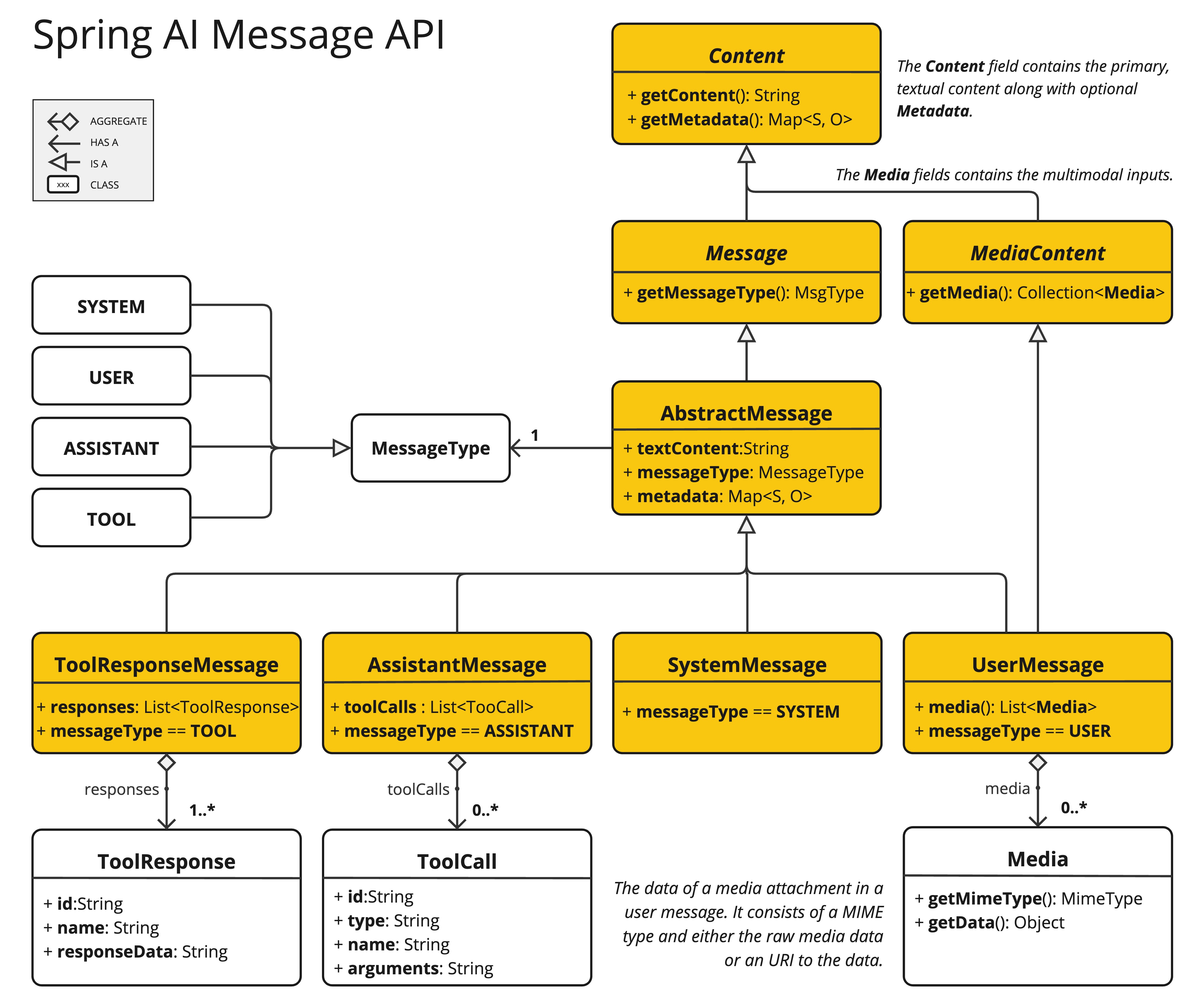
UserMessage的content字段主要用于文本输入,而可选的media字段允许添加一种或多种不同模态的内容,如图片、音频和视频。
MimeType用于指定模态类型。
根据所使用的LLMs,Media数据字段可以是作为Resource对象的原始媒体内容,或是指向内容的URI链接。
媒体字段目前仅适用于用户输入消息(例如,UserMessage)。对于系统消息,它没有意义。包含LLM响应的AssistantMessage只提供文本内容。要生成非文本媒体输出,您应使用专用的单一模态模型之一。 |
例如,我们可以将下图(multimodal.test.png)作为输入,要求LLM解释它所看到的内容。

对于大多数多模态大型语言模型,Spring AI 的代码可能会看起来像这样:
var imageResource = new ClassPathResource("/multimodal.test.png");
var userMessage = UserMessage.builder()
.text("Explain what do you see in this picture?") // content
.media(new Media(MimeTypeUtils.IMAGE_PNG, this.imageResource)) // media
.build();
ChatResponse response = chatModel.call(new Prompt(this.userMessage));或使用流畅的ChatClient API:
String response = ChatClient.create(chatModel).prompt()
.user(u -> u.text("Explain what do you see on this picture?")
.media(MimeTypeUtils.IMAGE_PNG, new ClassPathResource("/multimodal.test.png")))
.call()
.content();并生成如下的响应:
This is an image of a fruit bowl with a simple design. The bowl is made of metal with curved wire edges that create an open structure, allowing the fruit to be visible from all angles. Inside the bowl, there are two yellow bananas resting on top of what appears to be a red apple. The bananas are slightly overripe, as indicated by the brown spots on their peels. The bowl has a metal ring at the top, likely to serve as a handle for carrying. The bowl is placed on a flat surface with a neutral-colored background that provides a clear view of the fruit inside.
Spring AI 为以下聊天模型提供了多模态支持: